Como integrar Power Automate, Power BI e Copilot Studio em um fluxo de alertas
Preguiça de ler? Dá um GPT aí

Vamos começar
Quando comecei a montar essa integração entre Power Automate e Microsoft Copilot, senti falta de um material mais direto ao ponto. A ideia parece simples: coletar dados, enviar o contexto para um agente e devolver a resposta. Este post reúne alguns dos meus aprendizados e os "pulos do gato" que ninguém conta.
Antes de começar, acesse sua conta corporativa no Portal Microsoft e confirme se você possui uma licença do Copilot, como na imagem abaixo:
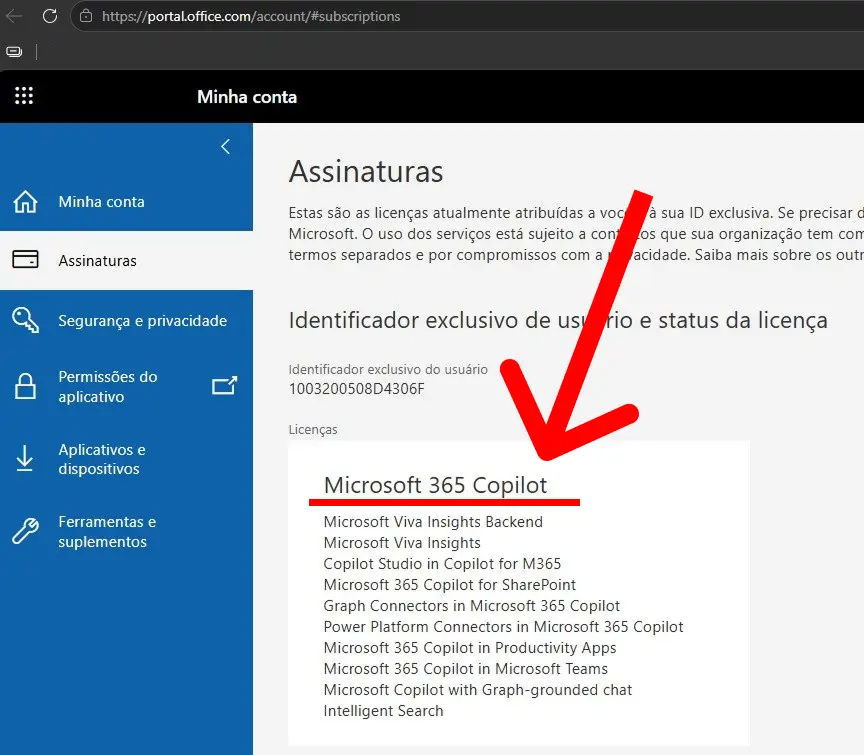
Se o resultado for positivo, então podemos continuar. Do contrário, você não conseguirá avançar.
Criando um Agente no Copilot
Com a licença confirmada, o próximo passo é criar o agente que vai interpretar os dados enviados pelo Power Automate. Acesse o Copilot Studio e siga o fluxo de criação — a configuração inicial leva menos de um minuto.
1. Nome do agente
Escolha um nome que identifique a função do agente no contexto do seu projeto. Neste exemplo, usei Rubens.
2. Instruções (Instructions)
Esse é o campo mais importante da configuração. É aqui que você define o papel, o tom e o escopo de análise do agente. No meu caso, orientei o Rubens a atuar como especialista em Supply Chain, com foco em identificar alertas e desvios relacionados a Spend e Prazo Médio de Pagamento (PMP). Ocultei algumas informações por questões de segurança, mas dê bons direcionamentos aqui.
3. Modelo de linguagem
Selecione o modelo que será utilizado pelo agente. Neste fluxo, estou usando o GPT-5 Chat, que oferece uma janela de contexto de 128K tokens
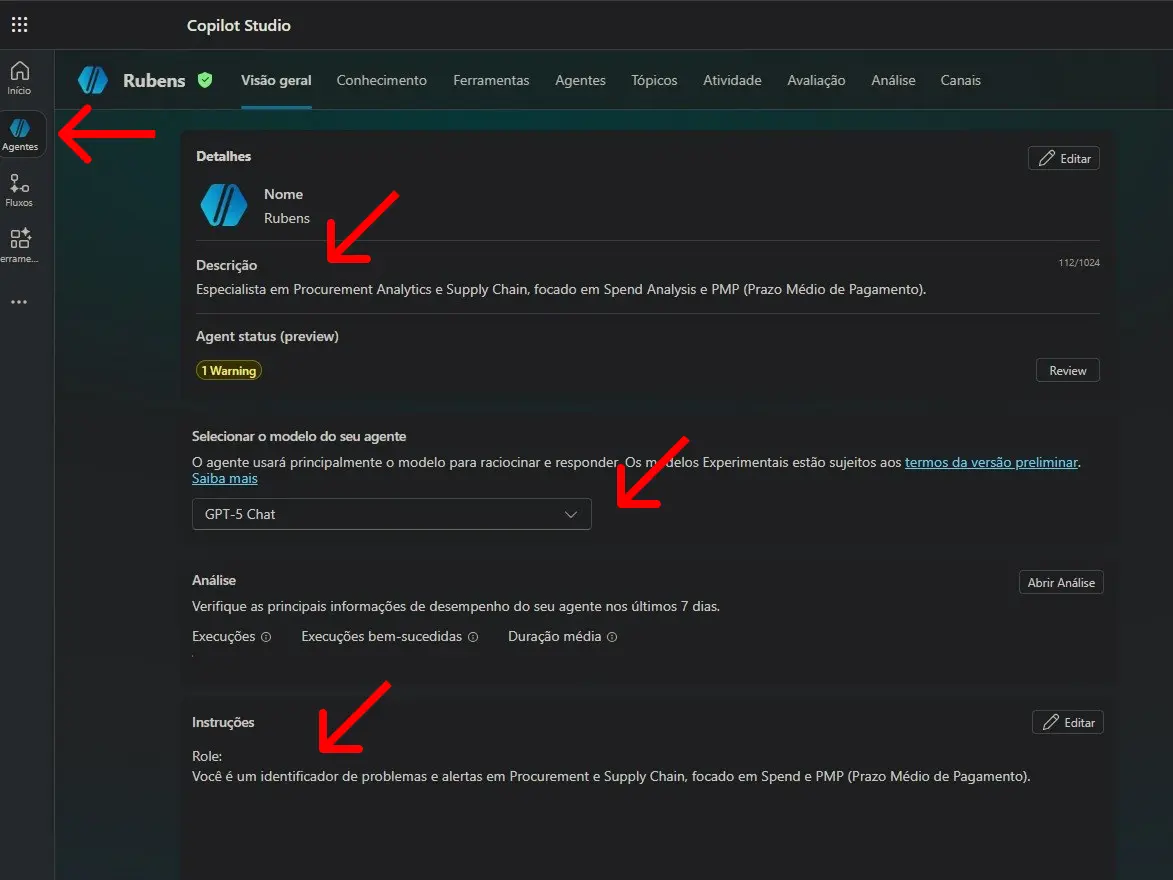
Repare que a tela de configuração (Overview > Instructions) concentra tudo que o agente precisa saber antes de receber qualquer dado. Quanto mais objetivo e específico for esse campo, mais consistente será a resposta gerada no fluxo.
A ideia por trás do fluxo
Neste projeto, uso o Power Automate como orquestrador para conectar uma fonte de dados no Power BI, enviar o contexto para um agente de IA no Copilot Studio e entregar o resultado formatado no Teams. Tudo acontece dentro do ecossistema Microsoft.
Esse fluxo surgiu para apoiar uma rotina de Supply Chain, mais especificamente o acompanhamento de gastos (Spend) e prazo médio de pagamento (PMP). A necessidade era identificar algunas alertas/desvios e avisar os gestores sem depender somente da consulta manual nos Dashboards. Ou seja, além dos dashboards que já existem na área, passamos a ter uma camada de notificação inteligente.
Adapte o relatório à sua lógica e ao seu cenário de negócios. Veja alguns exemplos de uso: alertas de vendas, resumos financeiros, relatórios de SLA ou qualquer outra análise recorrente.
Arquitetura do fluxo
O diagrama abaixo mostra de maneira compacta e visual como o fluxo está estruturado. A sequência vai do gatilho (manual ou agendado) até a entrega final no Teams.
Essa arquitetura separa bem as responsabilidades: o Power BI cuida da camada analítica (base de dados), o Power Automate orquestra a sequência, o Copilot Studio interpreta o conteúdo e o Teams entrega o resultado.
Estou usando o Power BI porque já tenho licença Pro, mas a lógica não depende disso. Você pode adaptar o fluxo para consumir arquivos xlsx ou .csv em um SharePoint, por exemplo.
O que cada etapa faz
O fluxo segue uma sequência linear, com 11 ações, 3 conectores principais e 1 agente no Copilot Studio. Analise a tabela abaixo para entender o funcionamento de cada etapa:
| Etapa no Power Automate | Descrição |
|---|---|
| Disparo | Inicia a execução do fluxo manualmente ou sob demanda. |
| VarPeríodo | Cria uma variável com a formatação do mês/ano corrente. |
| Consulta DAX | Executa a consulta DAX (otimizada) diretamente no modelo semântico do Power BI. O resultado desses dados está no formato JSON. |
| Parse JSON | Analisa e estrutura do retorno do Power BI para facilitar o acesso aos campos. |
| Transformação | Filtra e seleciona apenas as colunas necessárias para a análise. |
| Tabela CSV | O resultado da extração de dados do Power BI vem em JSON e, ao converter para CSV, consigo reduzir a quantidade de tokens que será enviada para o agente. |
| Token | Estima a quantidade de tokens antes do envio ao agente para reduzir o risco de estourar a janela de contexto e evitar erros de processamento. |
| Agente | Envia os dados consolidados para o Copilot Studio e aguarda a resposta do agente. |
| Resposta | Consolida e organiza o texto de retorno recebido do agente. |
| Notificação | Envia a análise e os insights gerados diretamente para o usuário no Teams. |
Decisões técnicas
Nesta seção, mostro as decisões que ajudaram a manter a automação mais simples de sustentar, com menos retrabalho e uma resposta mais útil no fim do processo.
Janela de Contexto
Antes mesmo de pensar no prompt, minha principal preocupação era mais básica: quanto dado eu poderia enviar sem quebrar o fluxo. Quem trabalha com IA sabe o peso que a janela de contexto tem. Quando você começa a mandar tabela, instrução, contexto e ainda espera uma resposta estruturada na volta, o risco de estourar esse limite é real.
Foi por isso que eu criei a variável de cálculo de tokens dentro do Power Automate. A ideia não era buscar precisão, mas ter um termômetro do volume enviado ao agente antes da chamada acontecer. Sem esse cuidado, você pode montar um fluxo que funciona em um teste pequeno e falha justamente quando recebe um conjunto maior de dados.
Segundo a documentação oficial do Copilot Studio, o contexto total é a soma de tudo o que participa da requisição:
Como a conta é feita
Total = "custo computacional" do Copilot Studio + instruções do agente + input (dados inseridos) do usuário + histórico + output esperado
Na prática, isso significa que não basta olhar apenas para a mensagem enviada pelo Power Automate. Existe uma parte invisível da conta que também consome contexto, como o prompt interno de orquestração do Copilot Studio, descrições de tópicos, ferramentas e camadas de segurança. Esse "custo computacional" não aparece de forma explícita no fluxo, mas pesa no limite final.
| Componente | Valor estimado | Observação |
|---|---|---|
| "Custo Computacional" do Copilot Studio | ~3K a 8K tokens | Inclui orquestração, descrições de tópicos e ferramentas, além de guardrails de segurança. |
| Instruções do agente | Variável | É o papel e comando que você define para o agente. No exemplo, configurei para ele ser um especialista em Supply Chain. Esse conteúdo é definido no Copilot Studio em Overview > Instructions. |
| Input do Power Automate | Variável | É o conteúdo enviado no campo message da ação Execute Agent and wait. Aqui é o prompt simples para que o agente análise o arquivo e retorne em HTM |
| Histórico | 0 | Na Proactive API, a conversa começa vazia quando o conversationId não é reaproveitado. |
| Output esperado | Variável | É a resposta que o modelo ainda precisa gerar. |
Abaixo está uma simulação real de uma amostragem de dados que enviei durante os testes usando o GPT-5 Chat. A janela de contexto desse modelo é de 128K tokens. Veja:
~5.000 (custo computacional)
+ 228 (instruções)
+ 7.905 (input)
+ 0 (histórico)
+ ~10.000 (output estimado)
= ~23.133 tokens (18% de 128k)Ou seja: esse cenário fica dentro do limite com bastante folga. Trouxe todo esse contexto, pois sofri com o erro: OpenAIModelTokenLimit
A explicação mais provável é que, em testes anteriores, o input estava grande demais ou o modelo usado tinha uma janela menor. A própria documentação deixa isso claro: cada modelo tem um tamanho máximo permitido para o input combinado, somando instruções, dados enviados e a resposta que ainda será gerada.
Esse ponto muda bastante a forma de projetar o fluxo. Não basta perguntar se o dado cabe. É preciso perguntar se o dado cabe junto com todo o resto que o modelo também precisa carregar para responder.
No meu caso, a variável de tokens passou a cumprir exatamente esse papel: evitar tentativa no escuro. Ela me ajuda a decidir quando reduzir colunas, resumir conteúdo, trocar o formato de envio ou até rever o modelo escolhido, antes que o erro apareça em tempo de execução.
DAX direto na ação do Power BI
O fluxo usa a ação de execução de consulta no Power BI, o que permite enviar DAX diretamente para o dataset.
Exemplo de consulta DAX
No fluxo real, o período não fica fixo. A etapa VarPeríodo monta esse valor e ele é injetado na consulta antes da execução. O exemplo abaixo mostra a estrutura com SUMMARIZECOLUMNS e TREATAS.
DEFINE
VAR FiltroPeriodo =
TREATAS({"VarPeríodo"}, 'dim_calendario'[mes_ano])
EVALUATE
SUMMARIZECOLUMNS(
'fato_basecompras'[GerenciaSupply],
'fato_basecompras'[Fornecedor],
FiltroPeriodo,
"ValorBruto", [Spend]
)Como conectar o agente
A chamada ao agente foi feita pelo conector do Microsoft Copilot Studio, usando a ação do tipo Agent and wait.
Comportamento do Agent and wait
O fluxo envia uma mensagem para o agente. O agente processa o contexto recebido. O Power Automate fica em espera até a resposta chegar. Quando a resposta é devolvida, o fluxo continua normalmente.
Foi exatamente nesse ponto que concentrei a instrução principal do fluxo. Para a resposta chegar de forma consistente no Microsoft Teams, o ideal é pedir um formato de saída objetivo e previsível. Meu prompt orienta o agente a responder em HTML simples, usando tags como <strong>, <br>, <h2> e <hr>.
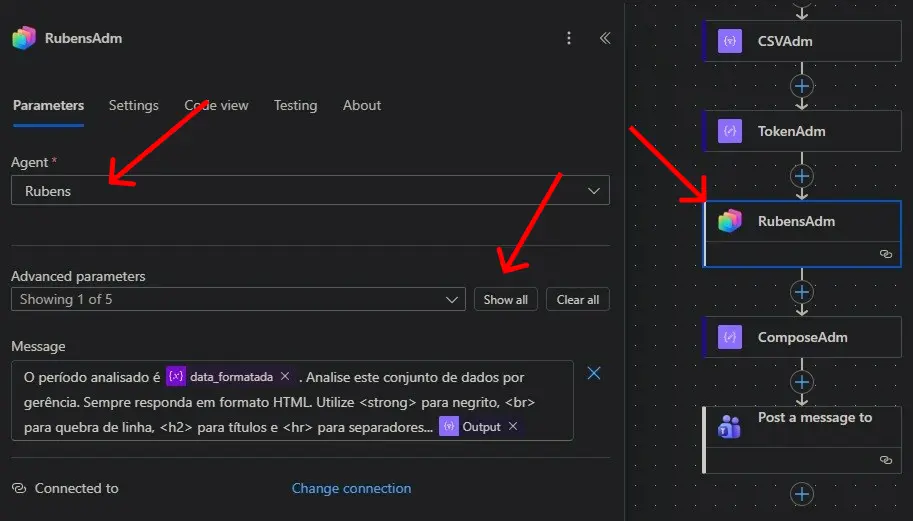
Com isso, o Teams passa a funcionar não só como canal de entrega, mas também como trilha de confirmação e log operacional. A mensagem já chega formatada e pronta para leitura, sem exigir que o destinatário abra outro sistema ou dashboard. Para alertas recorrentes, isso faz diferença: o gestor recebe a análise no mesmo lugar onde já acompanha o dia a dia.
Por que CSV em vez de JSON
Se você tivesse que apostar, qual formato consome menos tokens em um modelo de IA: JSON ou CSV?
Abaixo, comparo a mesma base simples de dados em JSON e em CSV para mostrar por que essa conversão faz sentido no fluxo.
JSON
[
{
"Fornecedor": "ABC",
"Spend": 15000,
"PMP": 45
},
{
"Fornecedor": "XYZ",
"Spend": 22000,
"PMP": 60
},
{
"Fornecedor": "DEF",
"Spend": 8000,
"PMP": 30
}
]Quantidade de caracteres: 205 ou 83 tokens (aproximadamente)
CSV
Fornecedor,Spend,PMP
ABC,15000,45
XYZ,22000,60
DEF,8000,30Quantidade de caracteres: 58 ou 26 tokens (aproximadamente)
A diferença parece pequena nesse exemplo, mas ela cresce rápido quando a tabela aumenta. No JSON, cada linha repete nomes de campos como "Fornecedor", "Spend" e "PMP", além de carregar aspas, chaves, colchetes, vírgulas e quebras de linha. No CSV, os nomes das colunas aparecem uma vez e o restante fica reduzido ao dado em si.
Foi por isso que escolhi trabalhar com CSV antes de enviar o conteúdo ao agente. A ideia era reduzir o volume do input e deixar o cálculo de tokens mais otimizado.
Decisão de custo
Para acompanhar isso dentro do Power Automate, criei uma fórmula simples através da etapa Compose que estima a quantidade de tokens baseado na quantidade de caracteres.
Eu divido a quantidade de caracteres por 2.5 para chegar a um valor mais próximo da realidade de tokens:
@{div(length(body('CSVAdm')), 2.5)}Como o conteúdo enviado ao modelo está em pt-BR, foi adotado o fator de 2,5 caracteres por token. Essa estimativa é mais conservadora, porque idiomas como o português normalmente consomem mais tokens do que o inglês, por causa da estrutura linguística e do uso de acentuação.
Se o conteúdo estivesse em en-US, uma aproximação comum seria usar 4 caracteres por token:
'@{div(length(body('CSVAdm')), 4)}'Vale ressaltar que essa é apenas uma estimativa, já que a quantidade real de tokens varia conforme o conteúdo processado pelo modelo.
Se quiser validar isso com mais precisão, a OpenAI disponibiliza um tokenizador oficial em clicando aqui.
Documentação e referências
Abaixo está a documentação oficial da Microsoft a respeito do Copilot Studio e que ajuda a reproduzir ou expandir esse fluxo com mais segurança e performance.
Conclusão: o que levar daqui
Ao longo deste artigo, cada decisão técnica foi pensada para resolver um problema real. Abaixo, reúno as principais lições em um checklist prático para você consultar ao montar seu próprio fluxo:
Checklist prático
1. Valide a licença antes de começar
Sem a assinatura do Copilot ativa, nenhuma etapa do agente vai funcionar. Confirme isso no portal Microsoft antes de investir tempo na montagem.
2. Estime tokens antes de enviar
Crie uma variável no Power Automate que divida o total de caracteres por 2.5 (pt-BR) ou 4 (en-US). Isso evita o erro OpenAIModelTokenLimit em tempo de execução.
3. Prefira CSV em vez de JSON
A conversão para CSV reduz drasticamente o volume de tokens. No exemplo deste artigo, a economia foi de ~83 para ~26 tokens na mesma amostra.
4. Considere o custo invisível do contexto
O Copilot Studio consome de 3K a 8K tokens só com orquestração interna, guardrails e descrições de tópicos. Some isso ao seu input antes de calcular se cabe na janela.
5. Peça HTML simples na saída
Tags como <strong>, <br>, <h2> e <hr> funcionam bem no Teams. Evite Markdown ou formatos que o conector não renderiza corretamente.
6. Use a ação "Agent and wait"
Ela garante que o Power Automate fique em espera até o agente devolver a resposta, mantendo o fluxo síncrono e previsível.
7. Adapte a fonte de dados
O Power BI foi usado aqui por conveniência (licença Pro já existente), mas a mesma lógica funciona com arquivos .xlsx ou .csv no SharePoint.
👇 Curtiu este conteúdo?
Se este conteúdo te ajudou, compartilhe com quem também trabalha com automação e dados.
Aproveite para conferir mais artigos.